这是上一篇的展开说说。
可持续运维解决的几个问题:
一,运维代码化后,运维操作相关的代码可复用。比如:同一套运维操作代码,在不同的服务器上都可以使用。只需拷贝一份运维操作相关的代码,执行一遍,就可以得到完全相同的 2 套服务;
二,运维代码化后,运维操作相关的代码可叠加使用。比如:安装 kafka 集群为例。部署 kafka 需要先安装 zookeeper,部署 codis 集群也需要安装 zookeeper。zookeeper 的运维操作代码化后,我们就可以在 kafka 和 codis 的运维操作代码中直接调用 zookeeper 的运维操作代码,类似拼积木一般,无需重复实现 zookeeper 的运维操作代码;
三、运维代码化后,运维数据可按需传入。比如:在不同的机房部署的 codis 集群,无论是密码还是集群名字都是不同的。代码化运维,运维数据会通过 jinja2 等模板语言抽象成变量;部署时,按需传入不同的变量值,就实现了不同 codis 集群的部署,从而实现了运维代码的自定义,提高了运维代码化的兼容性;
四、运维代码化后,运维数据的加密存储。比如:上一步提到了 codis 集群的数据,其中数据分为普通数据和私密数据,比如前面,codis 集群的名字就是普通数据,codis 集群的密码就是私密数据。运维代码化无论是普通数据还是加密数据,都会直接存放在 Git 等版本控制系统中,这样可以全面、简单的记录所有运维的操作,但私密数据是经过加密的,如下图:
普通数据
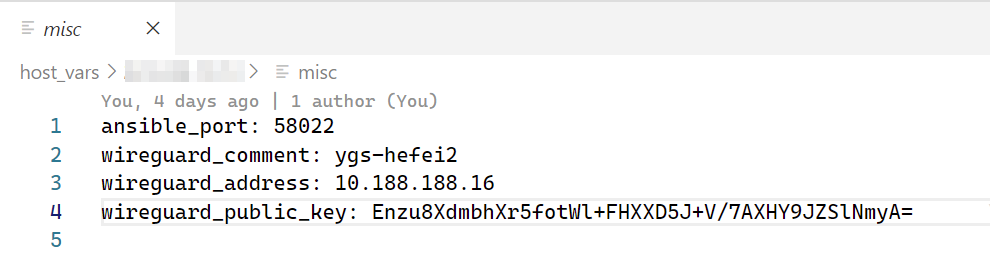
私密数据(未解密)
私密数据(已解密)

可以看到,私密数据,在没有解密的时候,是一串密文。无论是普通数据还是私密数据(解密后的),其实都是变量。运维数据加密存储可以实现人员权限的管理。比如,我们可以控制哪些人的公钥(一个人或多个人)可以解开私密数据。有权限的人(内部人员)才能成功的执行运维代码(实际情况中还会通过 SSH 公私钥实现更精细的服务器权限管理,管理谁可以操作哪些服务器,而运维数据的加密存储则是对内部数据的保护)。
运维数据加密存储也为运维协作带来可能,因为运维仓库内,实际上就只有运维操作和安全的运维数据。另外,可以把开源看作是大规模协作的一种形式,这种形式,不是走的最快,但会走得最远。
五、运维代码化后,运维操作的持续迭代。我喜欢使用开源软件,但维护几个、几十个开源软件的运行环境是痛苦的。举个例子:我本地的 Nginx 都是 HTTPS 加密的,这里就离不开 lego 和 dns-01 实现的自动证书申请和续期。我的内网 nginx、外网 nginx、gitlab、jira 都有一份证书,都需要创建和配置自动证书刷新,这是很消耗精力的。几个原因,一个是开源软件的持续迭代往往是 github、gitlab,国内网络不友好,下载更新体验差;其次,几个,几十个开源软件的运行环境持续更新,运维操作没有代码化的时候,手动运维时间和精力成本太大了,并且还有不少重复操作可能导致犯错。因此,将运维操作代码化,在可控人力成本(我一个人)条件下,实现稳定、高效、持续的更新非常重要,而这离不开 Git 和 CI 的支持。
我现在只需要在安装 nginx、gitlab、jira 的 playbook 内,调用这块的运维操作代码,如下图: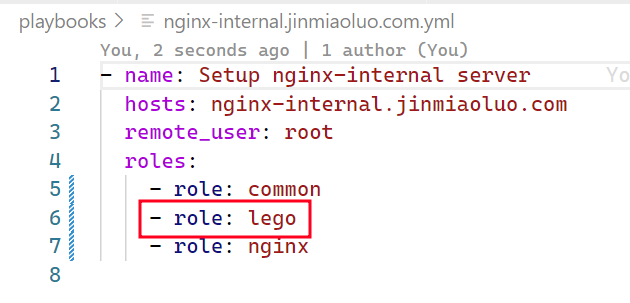
即可自动完成证书的申请(泛域名证书),并配置自动刷新所需的所有定时任务(如果你也尝试使用 dns-01 实现证书自动刷新,记得在自动刷新的时间点上加上一点随机性哦,避免刷新时间点冲突)。
另外,如果我需要更新 lego 这个开源组件,我只需更新 lego 版本对应的变量,提交改动到 Git,我的 CI 会自动下载最新的 lego,并更新所有服务器上的 lego 版本,如下图: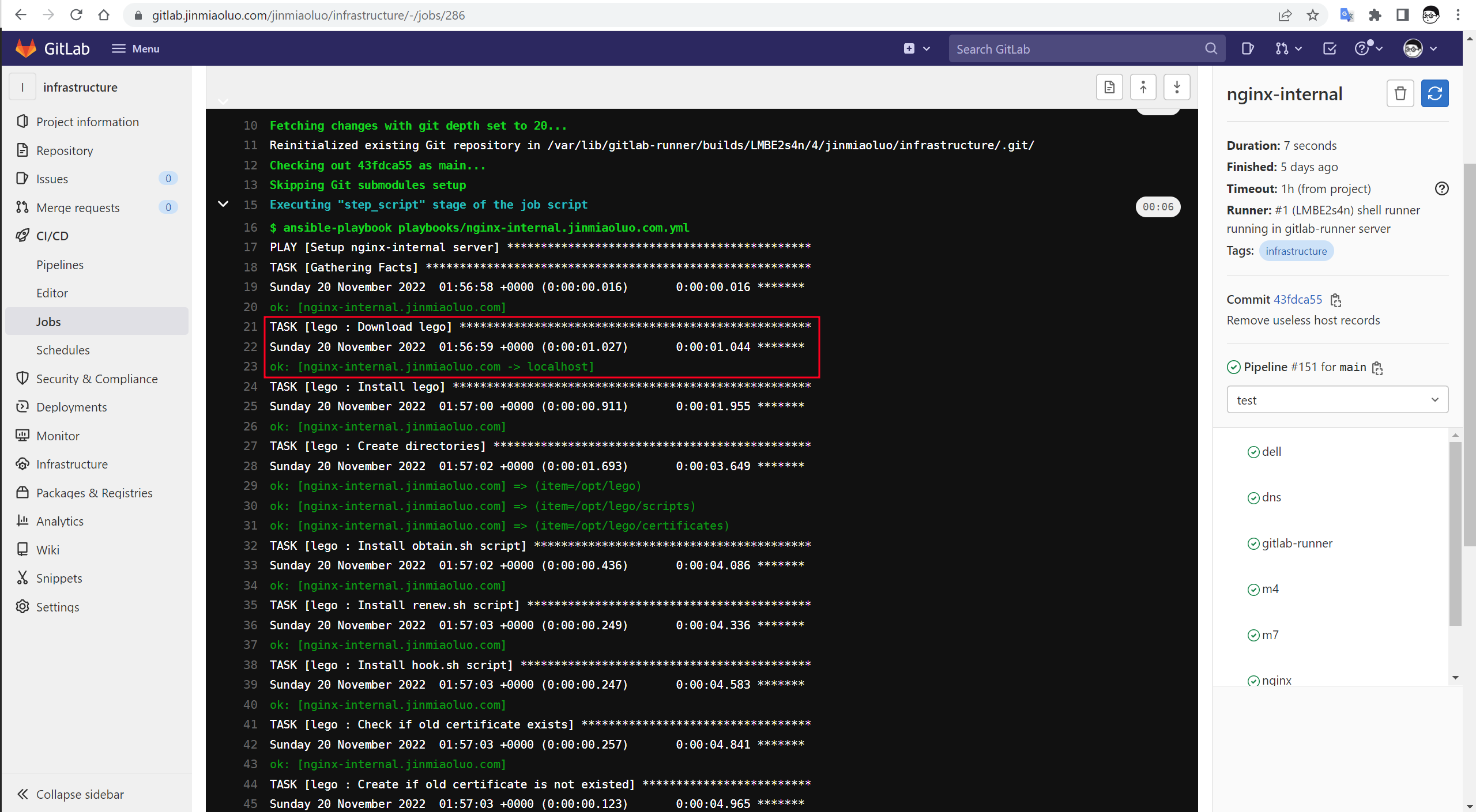
这一篇文章,主要还是解释一下,运维代码化中,操作和数据分离的必要性。代码化运维可以实现持续的优化、安全的权限控制和广泛的协同、高效的自动化。这也是可持续运维所需要的。